
| Added | Mon, 23/09/2019 |
| Источники | |
| Дата публикации | Fri, 07/06/2019
|
| Версии |
Researchers from Stanford and Princeton universities have created an algorithm that distorts a person's speech on video. For the credibility of the program not only adjusts voice and changes facial expressions, and the length of the roller.
According to the developers, their program is arranged this way: from the video it allocates the audio track, splitting human speech into phonemes. Further ON creates a 3D model of a human face, scanning as he moves his lips, saying the words. Then the machine finds wisely — sounds that look alike when lip movement and uses them to create facial expressions for the new phrase. In the end of the two spoken words, the algorithm generates a third.
Translated by «Yandex.Translator»

Source:
Новости со схожими версиями


During World War II, the United States tried to use luminous foxes against Japan
The mystery of a strange object in the sky over Sweden has been revealed
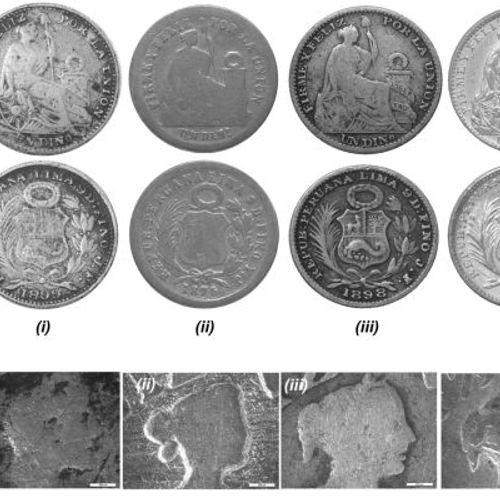
Scientists have revealed the secret of the "impossible" Peruvian coin of the late 19th century


Mummies in Mexico: A "deplorable and shameful fraud"

Log in or register to post comments